

What is DevOps? Who is DevOps? At a certain point each Ops asks: «Who am I?», «Why am I here?» and «What shall I do?» and this causes controversy and debates. At one point, you have current tasks that you need to do, at another point - logical and coherent DevOps architecture. In my opinion, logic is present in both things. That's why we need to pull into a history of the rise of DevOps culture to understand who is DevOps.
Let's abstract from the concept of what is DevOps and imagine that you have a business in developing some software. In such cases, you have some internal teams that are working on developing different components and services. Different teams act in different ways regardless of language/framework. Someone wants to use particular architecture solutions and others don’t have such an opportunity due to product specifications. In my reasoning, I take as a starting point the fact that all teams have different tasks and try to make them as accurate and simple as possible.
Ops
Even if you don't understand what is DevOps - you will get a point of understanding why development and operation are separate. After a while, it becomes clear that the teams, even if they solve different problems, face the same or similar problems. The solution for some of them will be the same regardless of the service.
Accordingly, the business thinks in such a way: if it is possible to single out something in common, then it is possible to form a department of people who will only deal with this and take advantage of it.
Savings on the difference in the cost of work
Imagine we have an expensive developer, whose rate is $70/hour. Then why should he do the work that a man can do at a cost of $35/hour? If it is possible to allocate all low-paid and simple work - it is possible to save a lot of money.
In addition, an expensive developer will perform complex and challenging tasks that he is interested in - and cheap ops will perform simple, which are not of interest to the developer.
Savings on inactivity
If there are people inside the team who are engaged only in ops tasks, then they will have idle time until the team generates new tasks.
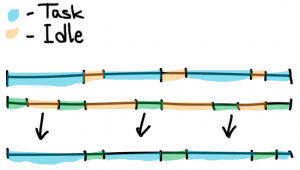
By uniting people in the general department, you can «distribute» them into several teams and benefit from it.
Savings on expertise
If there are tasks common to everyone, then different departments still come to about the same solutions. Development of expertise in several teams is always more expensive than containing several experts who will solve the problem both faster and better.
In addition, having several experts in rotation, you can not be afraid that someone will become irreplaceable simply because no one else can update the tricky setup.
Ops era
In the pre-DevOps era, it was customary to entrust a separate team with solving tasks of the following type:
- OS performance tuning (expertise);
- Database management (expertise);
- Working with another open source software (expertise);
- Monitoring (expertise);
- Updates delivering (expertise/cost);
- Performance improvement (expertise);
- Server/infrastructure administration&management (expertise/cost);
- Backup configuration&management (expertise/cost);
- Security hardening (expertise);
- Stable work delivering (expertise/cost);
- 24/7 emergency support (cost);
The funny thing is that almost everything from the list above is not a matter of cost, as we usually believe, but the issue of expertise: when people who know how to do something help other people who do not know how to do it. Thus, it is rarely possible to hire a cheap person who will be experienced and yet not against doing some routine garbage.
Separate teams?
Since it is impossible to occupy expensive specialists with routine and cheap specialists create garbage, usually within such a team, the structure of the division of requests is formed (evolutionarily or especially) depending on complexity.
It seems to sound great. But, as we all know the more hops - the higher latency is. Consequently, such a structure increases the time for solving any task.
The zero-sum game in business
Any person or a group of people almost always does only required tasks, not more. As a result, we have several teams that have new features in the priority, and a team that is responsible exclusively for stability. And if these teams have nothing in common, then the zero-sum game starts. And it does not end well for business: the ops want stability so much that they sabotage features and new technologies, and the developers want to do as little as possible about something other than features because it is this metric that judges business.

As a result, the culture within the companies suffers and competitiveness decreases. The business ceases to use all the opportunities that it could use. In addition, the problem of the growth of one department, the number of tasks that depends on other departments, is a very complex topic. We'll talk about this someday ;)
What is DevOps
After we faced these problems, we came to a simple solution: let's hire expensive specialists who will automate routine tasks, and with the help of all sorts of cultural pieces we will arrange a dialogue of people who support the product, with those who provide it. And on this point, we are close to understanding what is DevOps.
To reduce delays, we made teams of engineers responsible for both new features and the stability of the product because both things are a part of the service user experience. And features, and stability - this is the product. In addition, if it is necessary to set priorities between stability and speed then it is better to do it in one team, where they understand what is fraught with danger whether sitting at endless meetings of two teams with completely opposite goals.
Stability or features?
Here, the attentive reader will pay attention to the fact that almost everything that the ops department was engaged in is related to stability, and will be right. Therefore, the work of the ops should be made in a team that develops and uses the product.
I know this is a very loud statement. But what is DevOps and how will it help us? The problems that were faced in this transition were described at the beginning of the article, but let's think: can we solve these problems in a different way? What if we have a department that uses automation to clean up routine tasks and will have the necessary expertise to share it with other teams? Some problems can be solved by training and joint implementation, and others (including expert sharing) - scripts.
The ideal way things should be
A little common can become an internal product that this team will provide:
- OS performance tuning (automation/training/joint projects);
- Database management (automation/internal SaaS);
- Working with another open source software (automation/internal best practices/team responsibilities);
- Monitoring (automation/internal SaaS/training);
- Updates delivering (automation);
- Performance improvement (team responsibilities);
- Server/infrastructure administration&management (automation);
- Backup configuration&management (automation);
- Security hardening (expertise/training/automation/joint projects);
- Stable work delivering (automation/training);
- 24/7 emergency support (automation ?).
And it turns out that one team solves complex and general issues. And all the other teams do not follow how graphite is updated, or how the trends of dockers change. They simply use internal products and utilities, which are the best practices.
Responsibilities
No one writes their custom monitoring, no one comes up with their custom docker perversion - this is what a special team takes care of. By the way, you can read more about monitoring system organization in our recent article.
But if you want to receive metrics and deliver your applications to production, you have a set of utilities/practices that help to do this correctly, without stepping on the same rake. And do not reinvent the wheel every time and get expertise where you do not need it.
Such a scheme is convenient. The ops-team turns into a multi-team of engineers, which deals with everything that it can, and helps wherever it is needed. The list of tasks can also include rewriting / optimizing high-performance code, and internal PaaS, and simplifying the assembly/delivery of the application.
Production responsibility
And the rest of the product teams understand better how their code works in production, and it's good enough and sobering to the management and stability because if you are responsible for the user experience, you usually very quickly find the right and the most beneficial point between stability and new opportunities.
The above scheme, among other things, stimulates sharing of knowledge and experience instead of concentrating skills in one hand and additionally gives freedom where it is needed, solving the problem of scaling commands: do you want to use tarantula, mongo, queues, postgress? You do not have to beg the Ops to do it. Put and earn your experience. But you are also responsible for this.
And if everything goes right, then the winner is the one who takes responsibility, not the one who best shifts it to others. It's great, is not it? I hope you understand what is DevOps now.
Afterword
In order for a DevOps engineer to work efficiently, he needs to have a lot of energy and time invested. But beyond that, a lot of effort is necessary for support. We must constantly learn, constantly look for what can we do better, and do it better. It is necessary to think not only about today but also about what will happen tomorrow, in a month, in a year.
What is DevOps? On the part of this general expert team, we must always look at a few steps forward and try to make life easier for others. It is necessary to make products as autonomous and as moderately abstract. Such that they fit as many engineers as possible. Make it in such a way that other teams have as few problems as possible. And other product teams must take responsibility for their product, responsibility for the experience of their users, and constantly review their product from this particular experience.

Docker commands and Dockerfile usage for running containers on a local machine

Docker commands and Dockerfile usage for running containers on a local machine

Netflix tech stack for powering streaming backend and cloud solutions